
text2video论文阅读简记
Text2Video: Text-driven Talking-head Video Synthesis with Personalized Phoneme - Pose Dictionary
论文连接:https://arxiv.org/abs/2104.14631
GitHub代码地址:https://github.com/sibozhang/Text2Video (只有测试代码,没有训练部分)
演示视频:https://youtu.be/d5MFzHxeOTs
任务
以任意一段文字作为输入,生成一段表情和口型自然地念出这段文字的talking-head视频

动机
本文相较于基于语音的视频生成方法的三个优势:
- 仅仅需要很少的训练视频就可以完成预处理训练
- 由于采用了TTS,模型不会受到讲话者影响
- 处理,训练,推断速度大幅提升
方法
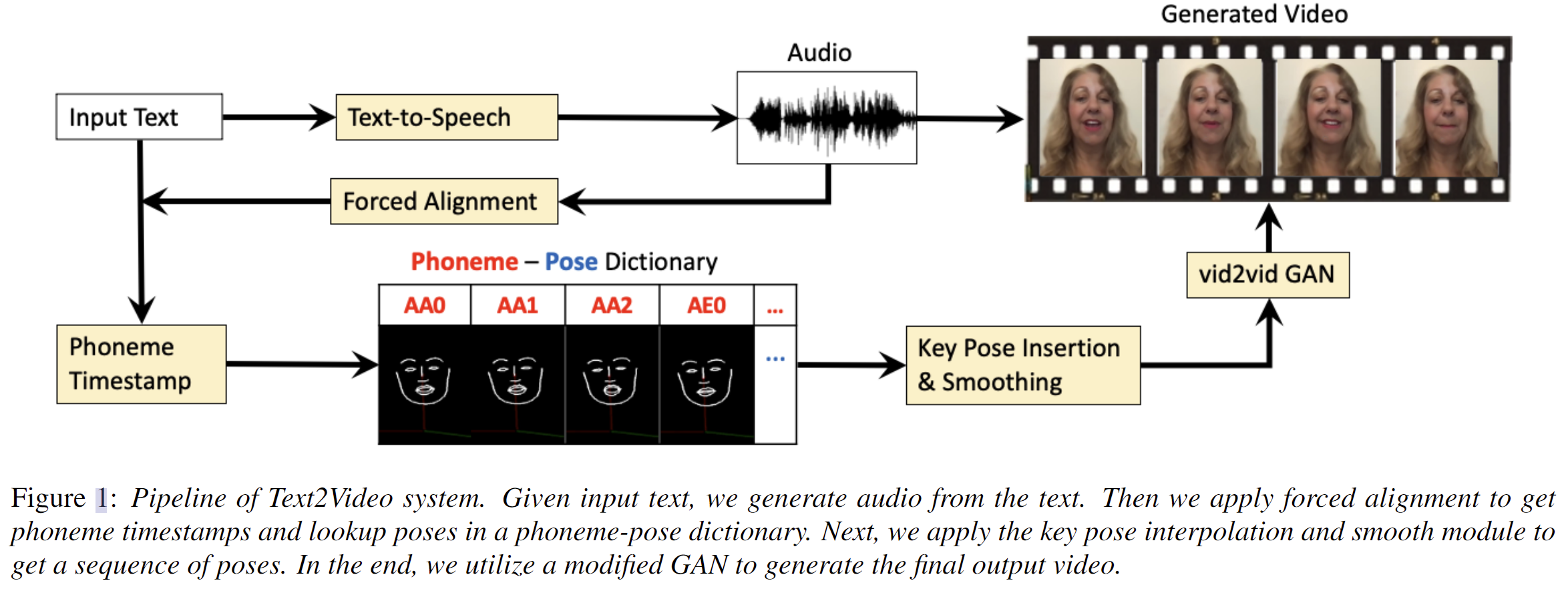
-
方法总体概述:给定输入文本,通过百度的TTS生成对应的语音,然后通过P2FA对齐器(aligner)将语音强制对齐获得语音的音素时间戳并在音素-姿态(phoneme-pose)字典中查找对应的音素姿态(phoneme poses),再通过关键姿态插值和平滑处理生成姿态序列,最后通过vid2vid GAN生成最终的视频
- 系统的输入的文本可以是任意形式(英文,中文,数字以及标点符号)
- 时间戳:每个文字在音频中的时间位置
-
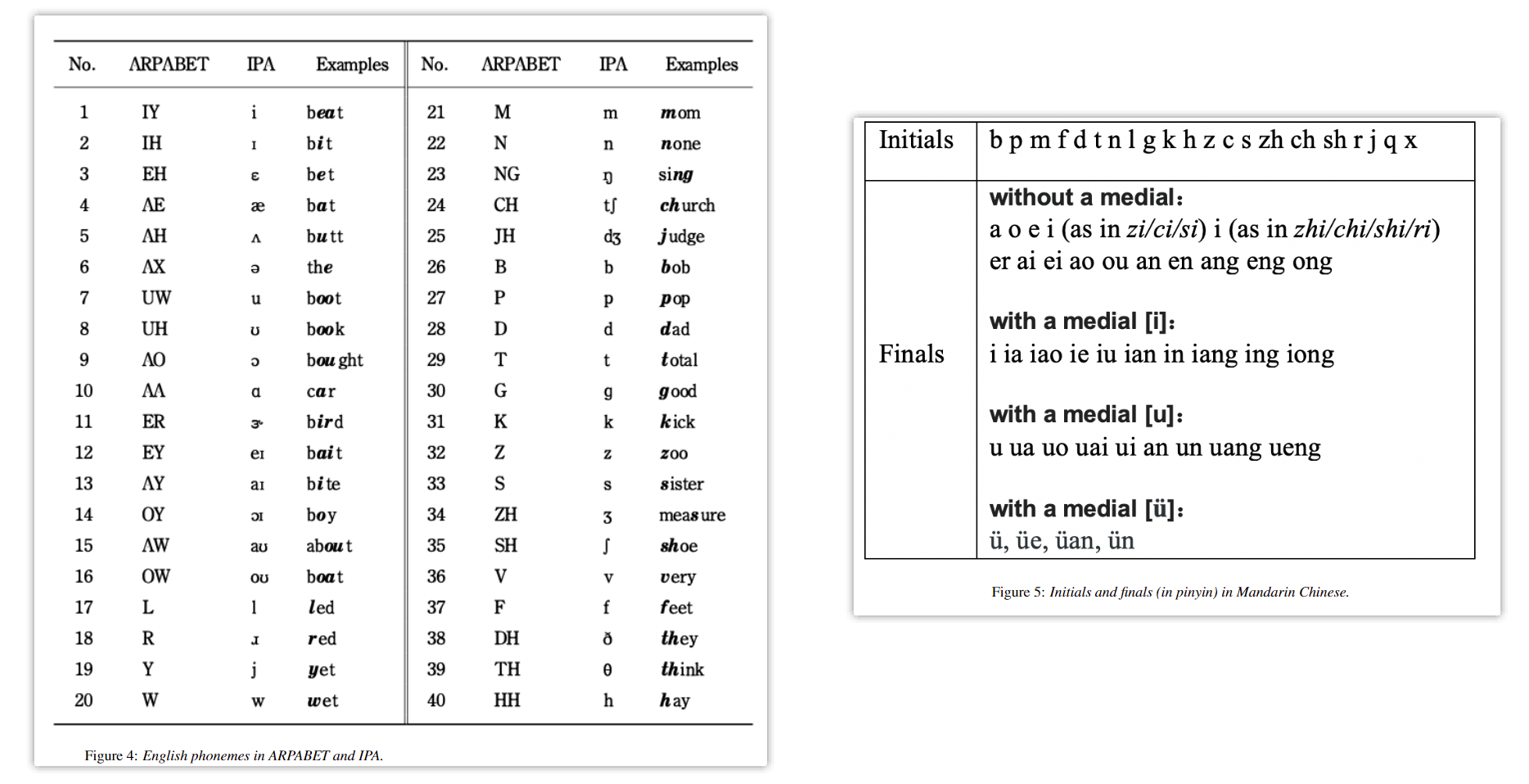
phoneme-pose字典生成:
- 英语音素表和汉字声韵母表
- 关键姿态抽取:使用Openpose从训练视频中通过平均所有的音素姿态提取关键口型姿态
- 音素抽取:使用了P2FA对齐器(aligner,来确定发声及其发声的时间位置。该任务需要两个输入:音频和单词转录。预先将转录的单词映射到 phone sequence中。通过比较观察到的语音信号和预训练的基于隐马尔可夫模型(HMM)的声学模型来确定phone boundaries。在强制对准中,语音信号被分析为连续的一组帧(例如,每10ms)。在给定观察数据和HMM表示的声学模型的情况下,通过找到最可能的隐藏状态序列来确定帧与音素的对齐方式。然后,根据对齐方式为字典中的每个音素存储pose sequences。根据数据集的视频帧速率和平均讲话速率来确定phoneme-poses的宽度。
-
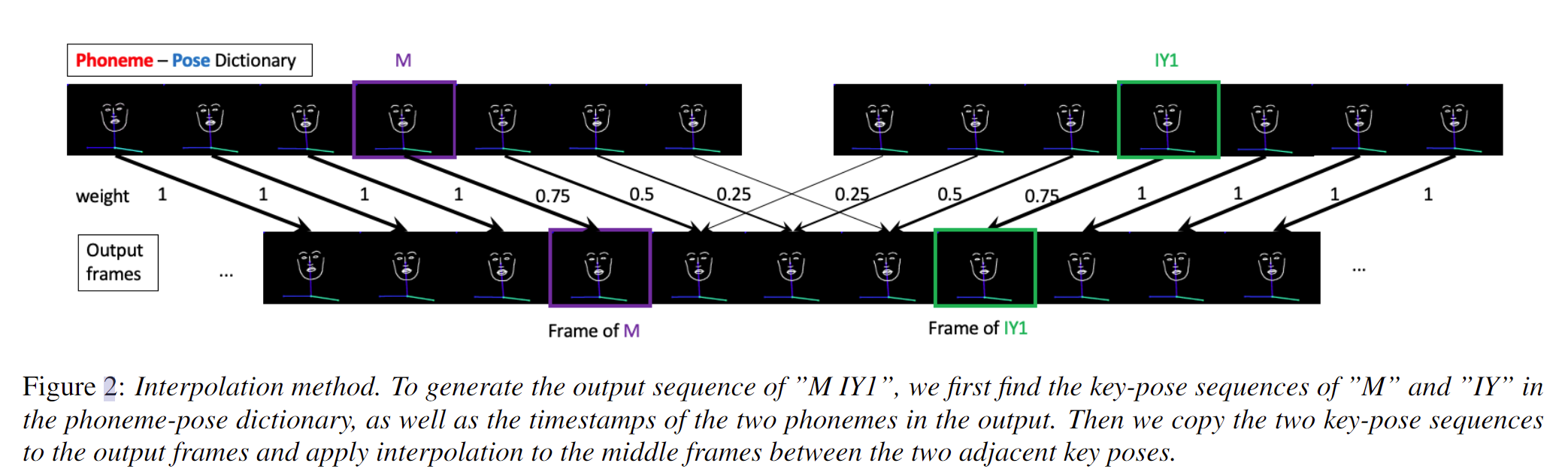
Key Pose Insertion:
- 如果两个音素关键姿势帧之间的间隔长度大于或等于最小关键姿势距离,我们将使用Key pose~i~ 和Key pose~i+1~进行插值。
- 如果两个音素关键姿态帧之间的间隔长度小于最小关键姿态距离,我们将跳过Key pose~i+1~,使用Key pose~i~和Key pose~i+2~进行插值。
- 最后使用插值将两个关键姿势序列之间的关键姿势与音素姿势的加权和混合,如图 下图所示。输出序列中的新帧被插值在两个关键姿势帧之间,根据它们与那些帧的距离加权两帧。权重与关键帧的距离成反比,即距离越大,权重越小。
- Smoothing:这里就是为了不影响精度对以嘴部为中心的区域不进行平滑处理
实验
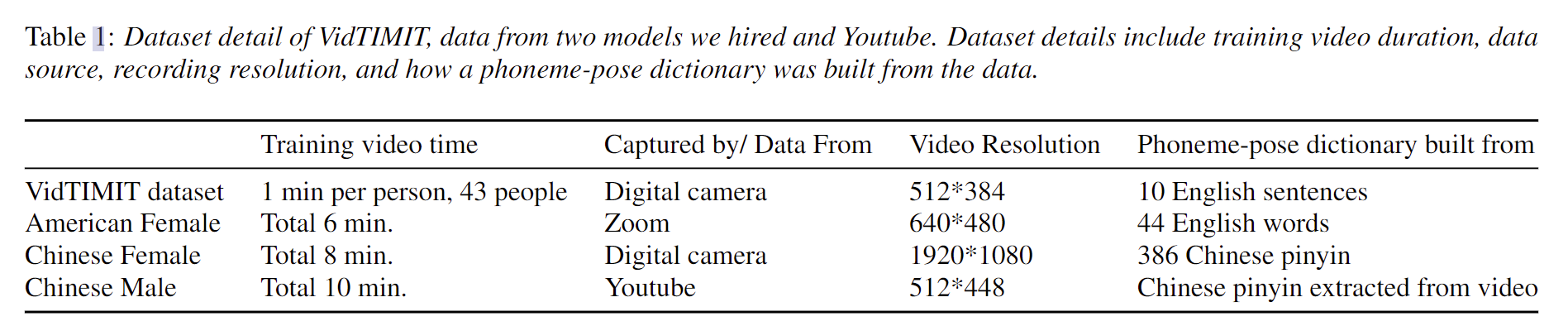
- 实验数据集相关信息
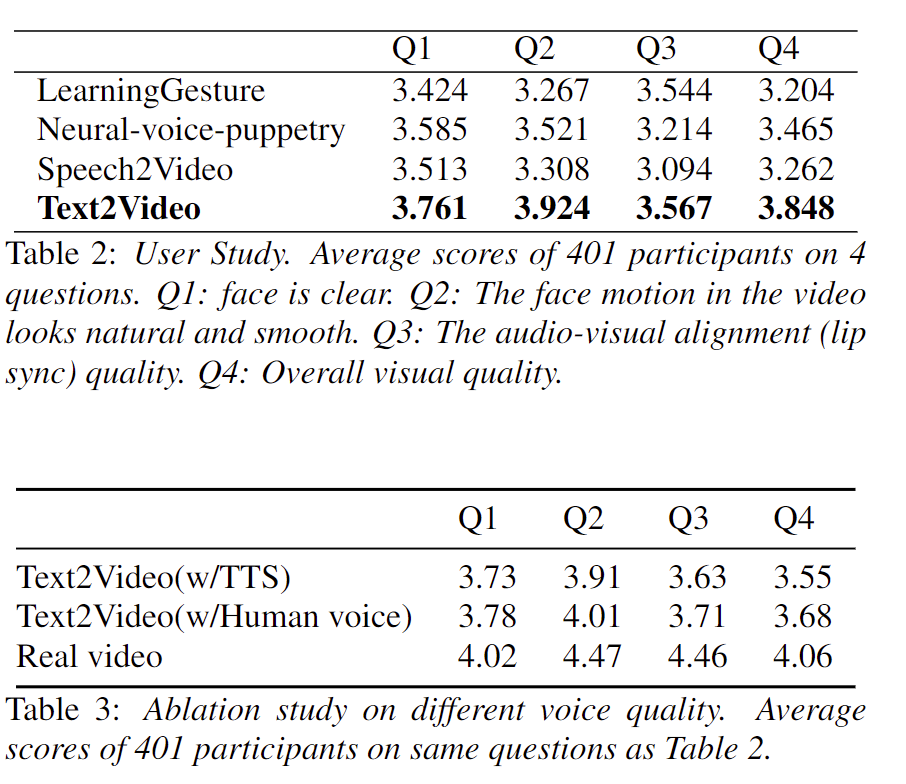
- 同其他audio-driven的sota方法效果比较(上),使用原视频文本生成不同类型声音版本跟原始视频进行比较(下)
- 生成过程可视化

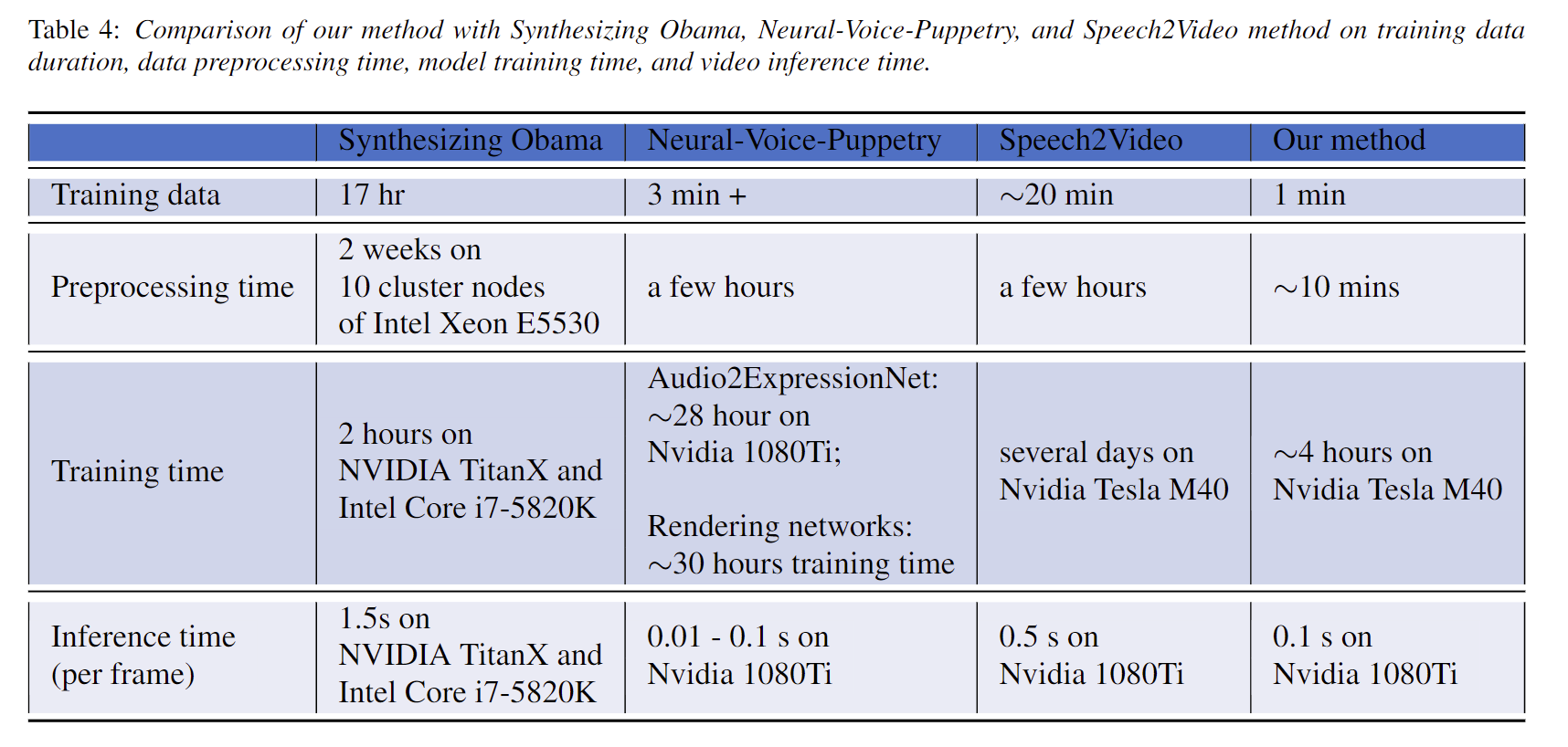
- 同其他方法训练,处理和推断时间的比较
自己的一些看法
- 最终作者的演示视频中展示的效果看起来怪怪的,而且评估指标均采用人为的主观评价,目前刚接触这一领域,感觉用这种方式去评估方法的好坏并不是很客观
- 而且我总觉得一般人说话除了口型外,面部表情大部分是跟语义相关的而并非语音,按照作者的这种方法,将音素同讲话者姿态绑定就会看起来怪怪的
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
论文连接:https://arxiv.org/abs/2103.11078
GitHub代码地址:https://github.com/YudongGuo/AD-NeRF
演示视频:https://v.youku.com/v_show/id_XNTEyNzY5MTA0NA==.html
动机
方法
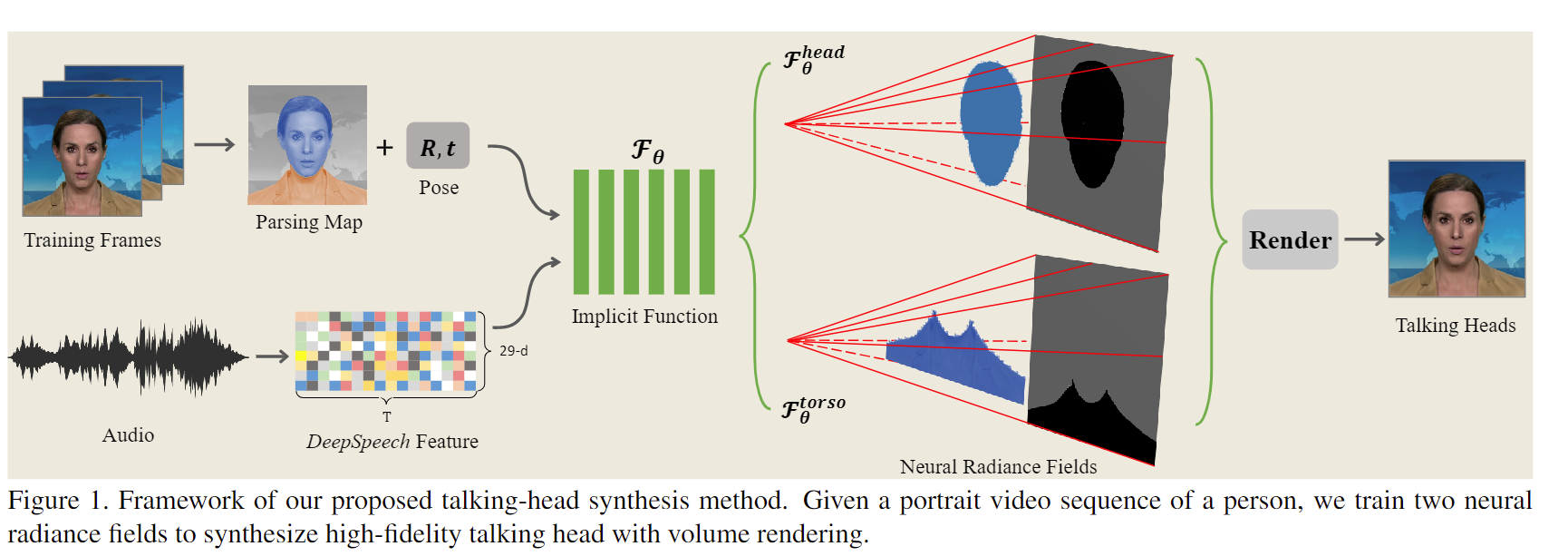
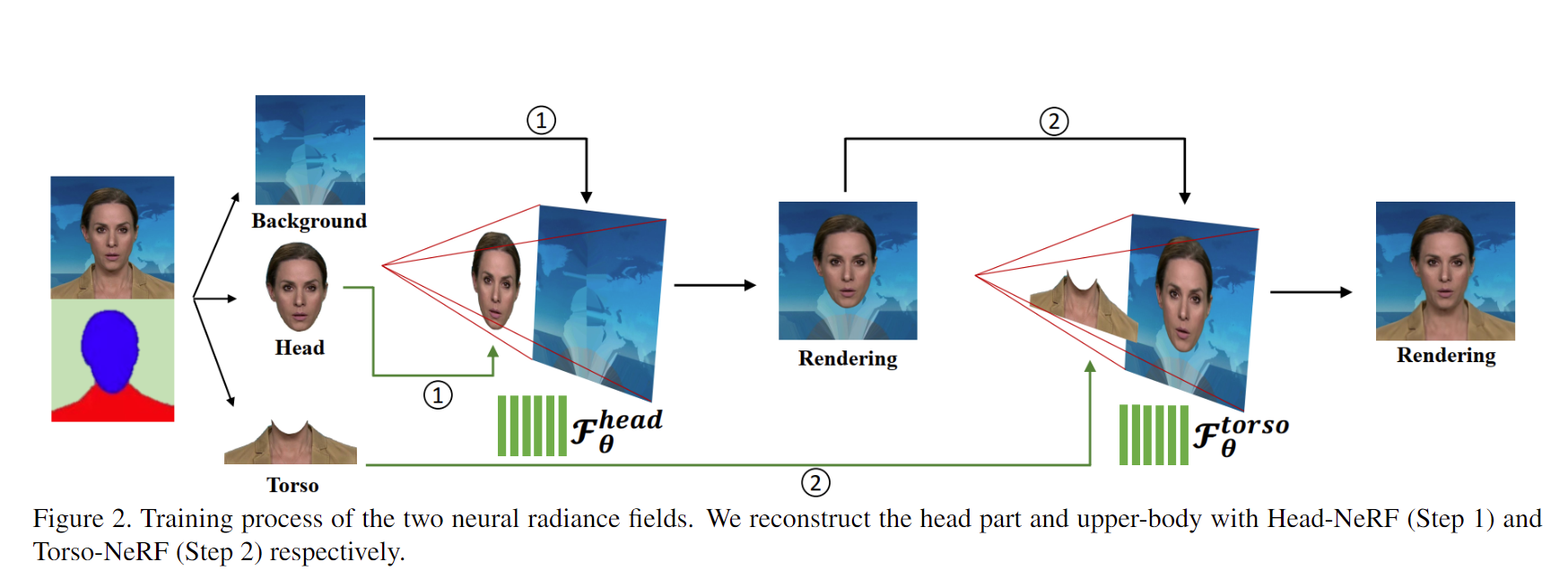
实验
自己的一些看法
- 实际跑下来,效果比较一般,整个训练过程时间比较长,不知道是哪里出了问题。
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose
论文连接:https://arxiv.org/pdf/2002.10137v2.pdf
GitHub代码地址:https://github.com/yiranran/Audio-driven-TalkingFace-HeadPose
演示视频:https://cg.cs.tsinghua.edu.cn/people/~Yongjin/video_arxiv.mp4
A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
论文连接:https://arxiv.org/pdf/2008.10010v1.pdf
GitHub代码地址:https://github.com/Rudrabha/Wav2Lip
演示视频:https://www.youtube.com/watch?v=0fXaDCZNOJc
任务 (内容简介)
文章所研究的问题任务如下图的左半部分:根据一段语音和一段talking-head视频生成口型同步视频,根据演示视频可以看到这篇文章最终的效果还是很不错的。
作者在文章开头就给出这项任务的若干非常有意义的实际应用场景
- 电影中配音的口型同步
- 高质量课程跨语言同步*
- 重要会议跨语言同步转播*
- 修复因某种情况缺失(或卡顿)画面的视频记录*

动机
这篇文章的主要贡献如下:
- 一个可以对任意语音和任意talking-head视频进行口型同步模型
- 重新定义了一种新的评估标准和指标
- 收集发布一个用于对任意视频进行口型同步的评估数据集ReSyncED
方法
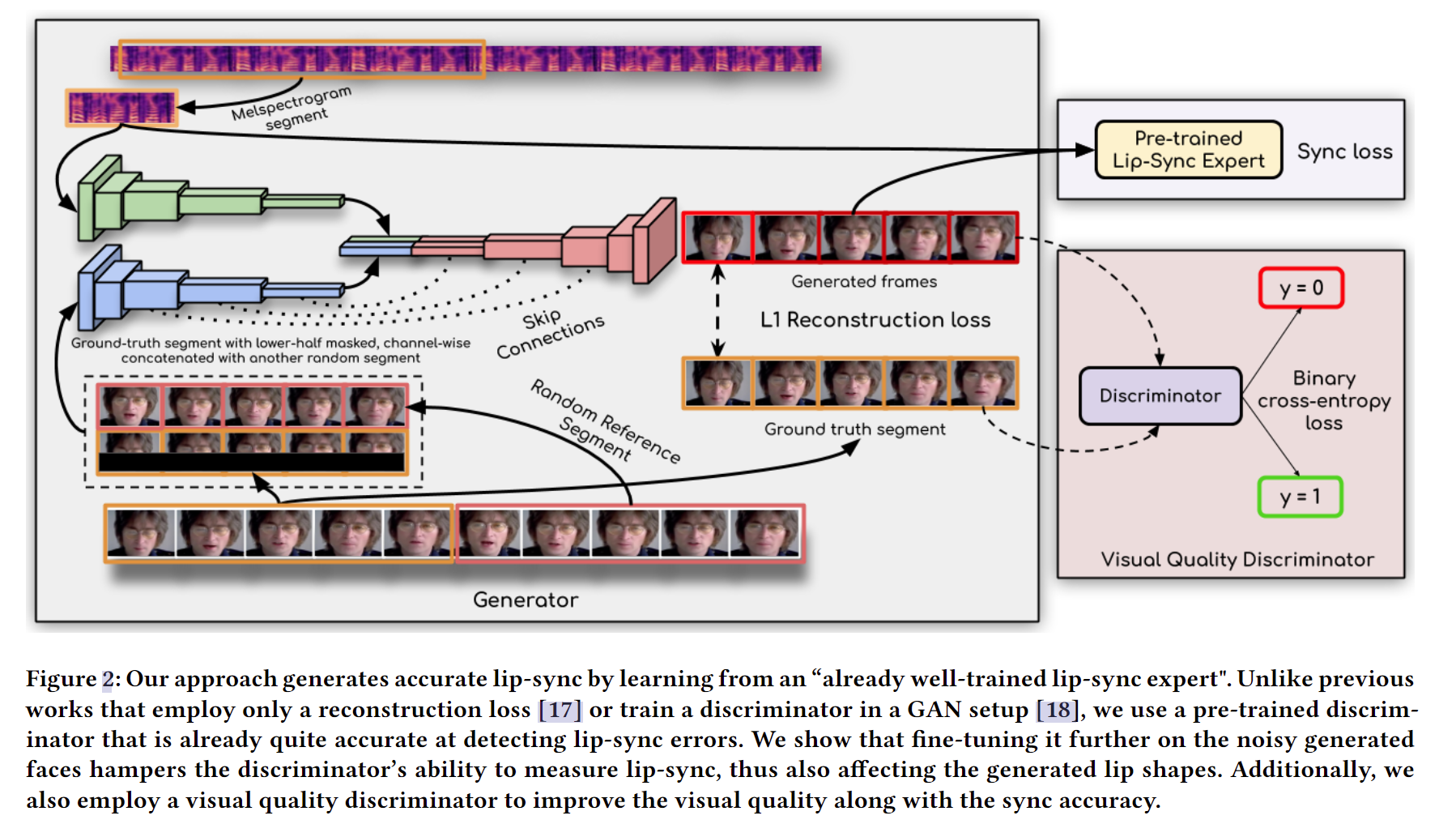
-
Pre-trained Lip-Sync Expert: 首先是全文重点介绍的口型同步鉴别器
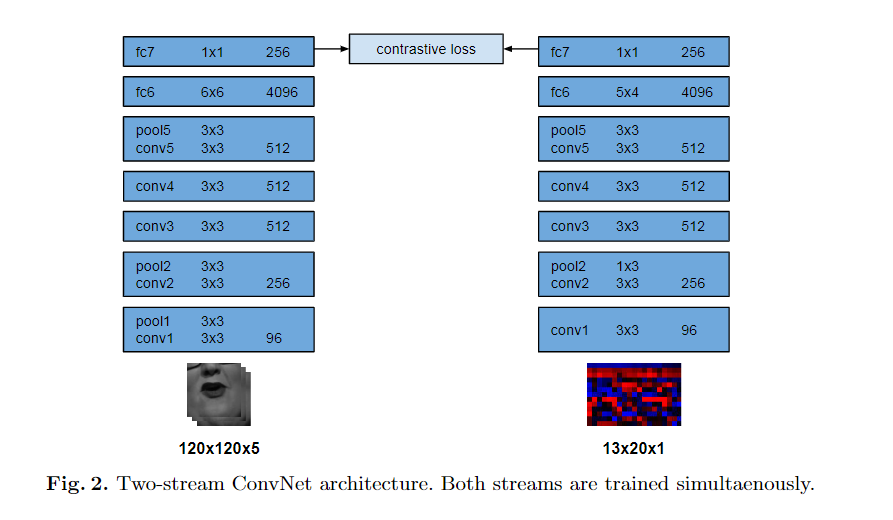
- SyncNet:下图是原始SynNet网络模型示意图,本文的口型同步鉴别器就是在这个网络的基础上修改训练得到的
- 彩色图像输入
- 卷积层中添加残差连接,卷积层更深
- 使用余弦相似度和二元交叉熵损失
- Sync loss:
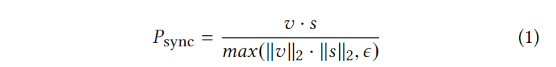
- SyncNet:下图是原始SynNet网络模型示意图,本文的口型同步鉴别器就是在这个网络的基础上修改训练得到的
-
整个模型简要概述:
- 输入:声音信号、对应的视频片段以及等长的随机视频片段
- 过程:声音信号通过语音编码器生成语音特征;随机视频片段同mask一半的对应视频进行concat后通过身份编码器生成身份特征;两个特征通过人脸解码器生成结果;结果视频片段和语音送入Pre-trained Lip-Sync Expert得到Sync loss;生成结果同对应视频片段进行比较得到L1重建损失;最后通过Video Quality Discriminator进行鉴别
-
模型生成架构的一些细节:(懒得用语言描述了直接上代码)
- 身份编码器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25self.face_encoder_blocks = nn.ModuleList([
nn.Sequential(Conv2d(6, 16, kernel_size=7, stride=1, padding=3)), # 96,96
nn.Sequential(Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # 48,48
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 24,24
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # 12,12
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(128, 256, kernel_size=3, stride=2, padding=1), # 6,6
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 3,3
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
nn.Sequential(Conv2d(512, 512, kernel_size=3, stride=1, padding=0), # 1, 1
Conv2d(512, 512, kernel_size=1, stride=1, padding=0)),])- 语音编码器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18self.audio_encoder = nn.Sequential(
Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(32, 64, kernel_size=3, stride=(3, 1), padding=1),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 128, kernel_size=3, stride=3, padding=1),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 256, kernel_size=3, stride=(3, 2), padding=1),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(256, 512, kernel_size=3, stride=1, padding=0),
Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)- 人脸解码器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25self.face_decoder_blocks = nn.ModuleList([
nn.Sequential(Conv2d(512, 512, kernel_size=1, stride=1, padding=0),),
nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=1, padding=0), # 3,3
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),), # 6, 6
nn.Sequential(Conv2dTranspose(768, 384, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),), # 12, 12
nn.Sequential(Conv2dTranspose(512, 256, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),), # 24, 24
nn.Sequential(Conv2dTranspose(320, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),), # 48, 48
nn.Sequential(Conv2dTranspose(160, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),),]) # 96,96- L1重建损失: 生成图像与真值图的像素级的L1损失
-
Video Quality Discriminator(视觉质量鉴别器): 这个在代码中还没看明白
-
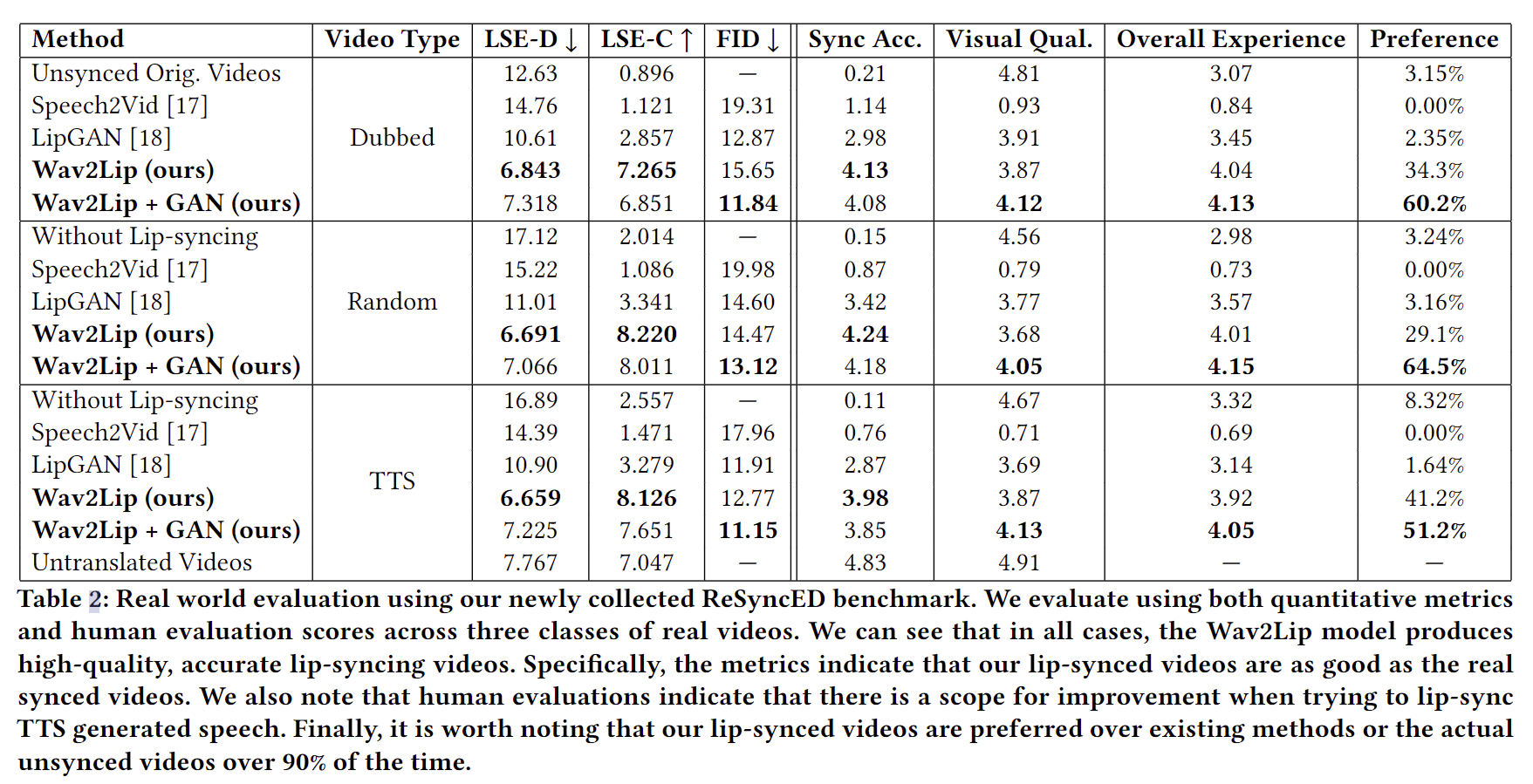
评估指标
- LSE-D,这个指标是通过计算SyncNet中的口型和音频特征之间的距离的平均误差。该指标越低表示视听匹配越好,即语音和嘴唇运动是同步的。
- LSE-C,这个指标是平均置信度。该指标越高表示音视频的相关性越好。
-
ReSyncED数据集
- 所有的视频音频均来自Youtube,然后主要分成下面三类
- Dubbed,音频不同步。主要包括一些配音的电影造成的音频错位以及翻译成其他语言后导致的音频不一致问题的视频
- Random,这个随机就是说,随便从某个视频截取一段语音然后同另一个视频(或者这个视频的另一段)组成一个音频(audio-visual)对
- TTS,文本转语音,然后和一些原始视频进行组合
实验
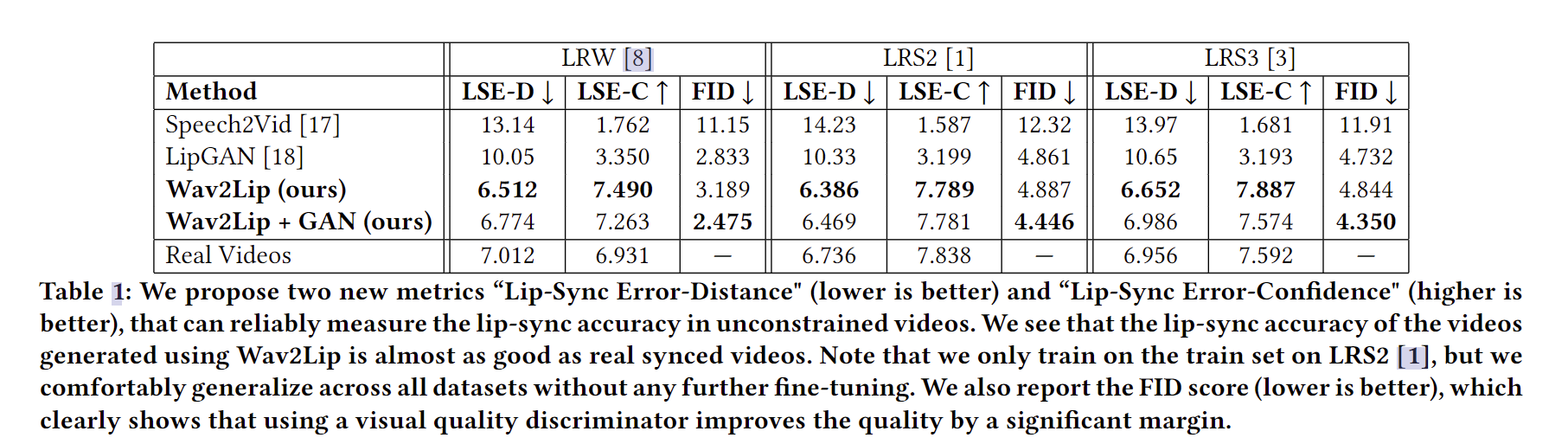
自己的一些看法
- 直接用作者提供的通过LRS2数据集训练得到的权重对一段视频和随机的语音进行生成,效果非常不错,但仍存在一定的伪影以及部分不说话的情况下嘴唇仍然在动的现象。
- 后续有文章在此基础上添加了注意力机制进一步提升性能
- 同TTS进行结合可以变成txt2video模型
MakeItTalk: Speaker-Aware Talking-Head Animation
论文连接:https://arxiv.org/pdf/2004.12992v3.pdf
GitHub代码地址:https://github.com/yzhou359/MakeItTalk
演示视频:https://people.umass.edu/yangzhou/MakeItTalk/
https://zhuanlan.zhihu.com/p/410570384
任务 内容简介
动机
方法
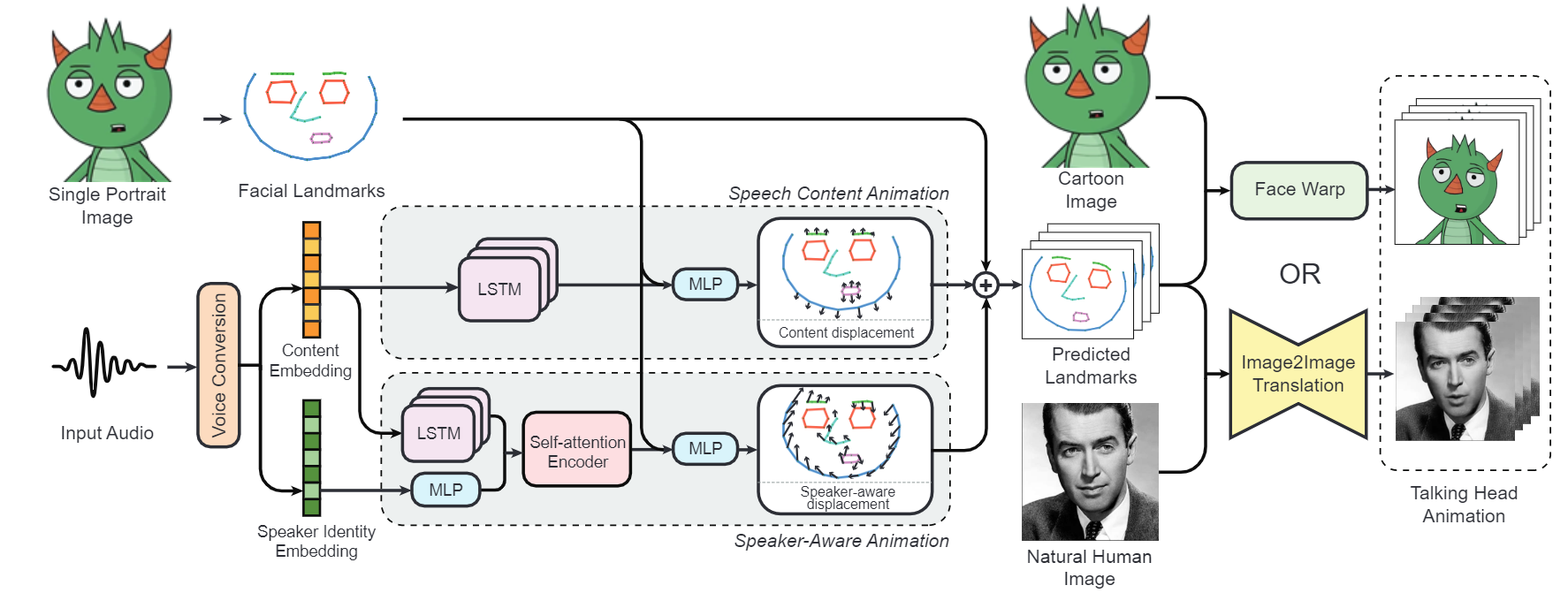
实验
自己的一些看法
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
论文连接:https://arxiv.org/abs/2104.11116
GitHub代码地址:https://github.com/Hangz-nju-cuhk/Talking-Face_PC-AVS
演示视频:https://hangz-nju-cuhk.github.io/projects/PC-AVS
任务 内容简介
动机
方法
实验
自己的一些看法