
论文简记
CLIP:Learning Transferable Visual Models From Natural Language Supervision
(2022.2.13)
简要介绍
论文连接:https://arxiv.org/pdf/2103.00020.pdf
GitHub代码地址:https://github.com/OpenAI/CLIP
简要描述:作者认为像用类似ImageNet数据集中有1000个固定类别做预训练,限制了模型做迁移的泛化性和扩展性。因此作者设计了一个新的预训练任务——通过图片直接预测对应的文本,为此作者团队从网上爬取大量的<图片,文本>数据样本形成了一个包含4亿样本的数据集。通过该数据集做预训练最终在不用一张imageNet数据集中图片(Zero-shot)的情况下可以和ResNet-50打成平手(top-1准确率76.2%)且在相关的下游任务中,zero-shot有更好的表现
关键性的概念及内容
- 模型迁移学习过程
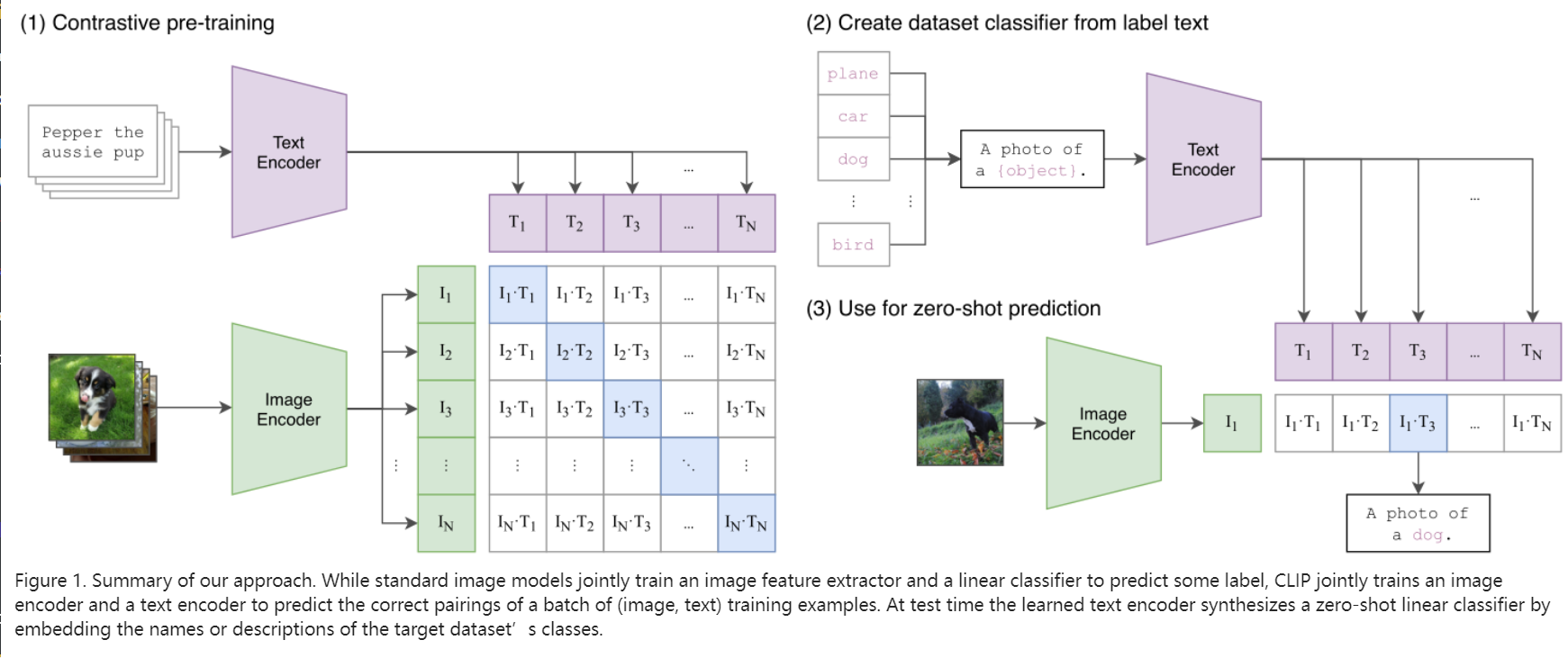
- 首先预训练阶段,对样本中的文本和图片分别进行编码。这里的编码器可以是ResNet-50这种卷积神经网络,也可以是Transformer这种。论文中效果最好的是采用的 ViT-L/14@336px这一模型。图中主对角线就是正例,其余特征的结合均为反例
- 将预训练好的模型迁移到新的任务上时,可以先进行简单的提示工程。如果是imageNet的话就是将一千个类别变成一千句话然后进行特征提取。提示工程具体来说就是假设有一个数据集中都是食物,那么第二步中就可以是a food photo of {object}。由于在预训练过程中模型是真的学到了图片对应的语义信息,因此这样的语义提示会有很好的效果。
- 如果是采用zero-shot模式的话,就直接对图片进行特征提取,同前面的文字特征进行结合的到最终的结果
-
迁移学习的形式
-
zero-shot : 在不用新数据集中任何一个样本的情况下进行迁移的形式
-
few-shot:仅对新数据集中每类使用少量的样本进行微调的过程
-
linear-probe: 将预训练的主干网络中的参数冻住,然后用全部新的数据集对尾部的分类或者具体任务进行微调的过程
-
-
zero-shot是一个比较显眼的成果,但实际上论文中linear-probe的效果才是真正令人惊艳的,真正意义上能应用到更多的领域
个人的一些想法
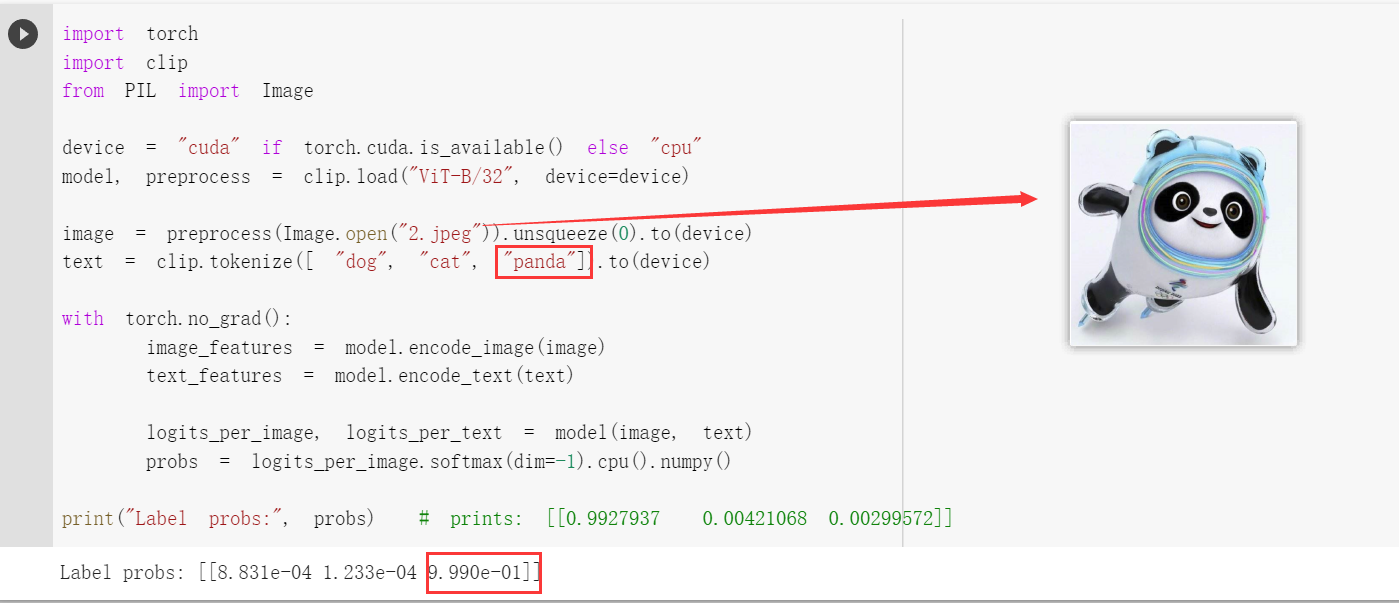
- 我用冰墩墩和鞭炮做了一个简单的尝试,可以看到模型99.9%的认为这是一个熊猫,甚至于我把英文换成拼音xiongmao它也基本认定和这个图片有关(0.95)。还有就是在用鞭炮图片的时候我用中文它也有0.85认为和图片有关系。所以我很好奇是因为作者团队所创建的数据集过于庞大真的囊括大部分情况使得模型准确率如此高,还是说模型真的学到了文本和图片中的语义信息。
- 作者自己在局限性章节指出,他们选用这些数据集做实验虽然数量很多,但是实验次数多了以后难免引入部分过拟合。模型的扩展性和泛化性需要进一步探究。
- 是否可以利用医学图像区域分割的数据集对该模型进行linear-probe。本身医学图像的数据集普遍都比较小,该模型在zero-shot和few-shot都有非常不错的表现,如果能够通过linear=probe进行微调将模型迁移到医学图像分割问题上感觉是个人感觉是可以取得不错的效果的。
ConvNeXt:A ConvNet for the 2020s
(2022.2.16)
简要介绍
论文连接:https://arxiv.org/pdf/2201.03545v1.pdf
GitHub代码地址: https://github.com/facebookresearch/ConvNeXt
简要描述:近几年随着VIT和Swin-Transformer的出现,相比于卷积神经网络(Conv),Transformer系列的架构在许多视觉任务上都表现的十分突出,因此研究人员普遍都认同Transformer这种结构在本质上优于Conv,能够在大规模参数的情况下得到更优异的成果。但作者团队却认为现阶段的transformer或者conv+transformer本质上都是相同的,造成效果不同的原因是优化策略,所以这篇论文就按照swin-transformer中的思路对resnet进行了充分的优化,最终在ImageNet数据集上取得和swin-Transformer同样的结果(top-1准确率:87.8%),在下游任务中基本都略优于transformer。
参考博客:ConvNeXt网络详解
核心内容
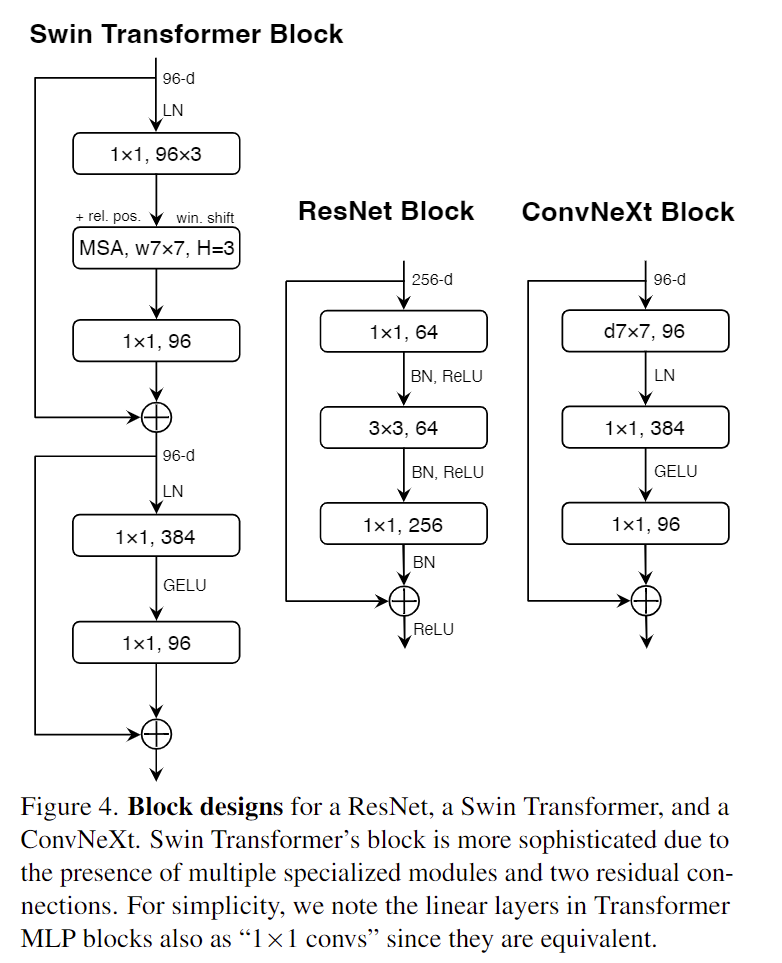
基本上这张图片就可以算是整篇论文的核心
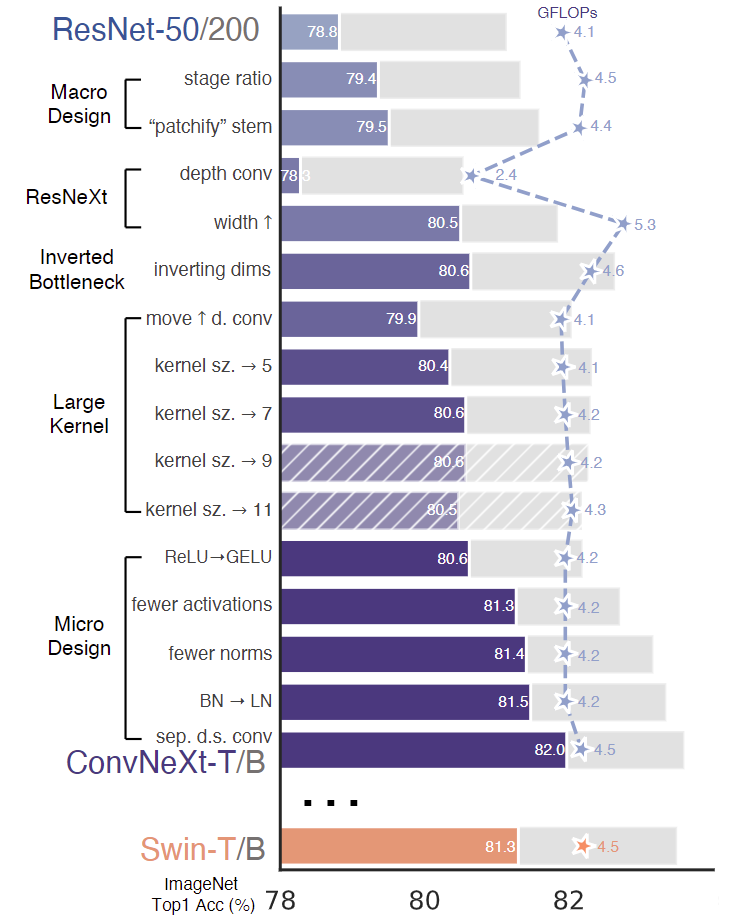
- Macro design
- stage ratio, 作者从宏观角度发现ResNet-50中模块堆叠比例是(3,4,6,3),但在swin-T中是(1,1,3,1),在大型的swin-T甚至达到(1,1,9,1),因此将ResNet中堆叠比例修改成(3,3,9,3)。准确率由78.8%提升到79.4%
- Changing stem to “Patchify”,在transformer中通常是使用不重叠的卷积层进行下采样(卷积核大小=步长),swin-T中使用的ks=4x4,stride=4,因此修改后的ResNet也采用该方式进行下采样。准确率提升了0.1%到79.5%,这步个人感觉意义不大更多是为了跟swin-T保持一致。
- ResNeXt-ify,这一步主要是借鉴了ResNeXt中组卷积可以降低计算量提高准确率,将原始ResNet中瓶颈结构的3x3替换成组卷积。作者觉得
depthwise convolution和self-attention中的加权求和操作类似,因此将dw conv的组数设置和通道数相同,最后准确率提升到80.5%- dw conv 和pw conv 含义作用可以参考这篇文章: https://blog.csdn.net/tintinetmilou/article/details/81607721
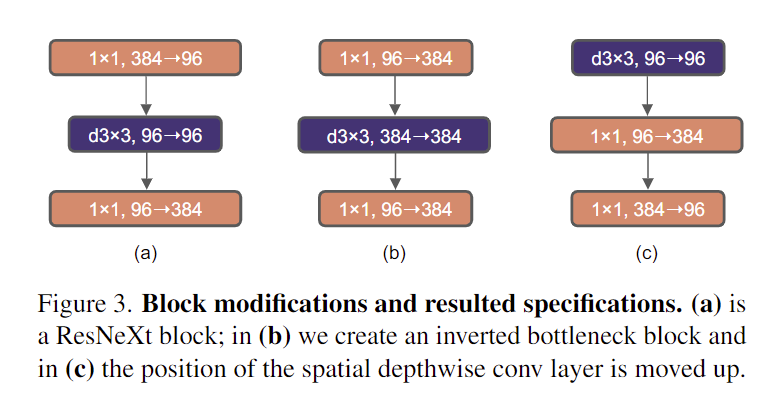
- Inverted Bottleneck, 反瓶颈结构。在原始的ResNet中采用(大-小-大)的形式减少计算量,但是后面有人认为这样会损失空间信息应该采用图3 b中(小-大-小)的形式(b中最后的1x1应该是384=>96),Transformer中MLP也有类似的设计,所以最后修改的ResNet采用了图4中所示的结构。最后准确率提升到80.6%
- Large kernel, 自VGGNet后基本上卷积神经网络都采用的小卷积核(3x3),但在transformer中大多都采用很大的卷积核,所以这里也同样进行效仿
- Moving up depthwise conv layer,把dw conv移动到1x1卷积前面,这里主要是参照在transformer中 MSA模块在MLP前面。准确度降低到79.9%同时计算量也有所下降
- Increasing the kernel size,尝试增大卷积核,最后实验表明7x7卷积核效果最好,包括在较大的ResNet-200中也是如此。在计算量几乎没有改变的情况下,准确率提高到了80.6%。
- Micro Design,一些微观层面的设计
- ReLU=>GELU,准确率没变化,主要是在最新的一些transformer中用到了这种激活函数就把GELU应用到卷积网络中。(感觉作用不是很大)
- Fewer activation functions,在transformer的一个模块中除了最后的MLP中有激活函数其余均没有,因此将ResNet中除了两个1x1卷积间的激活函数外均去掉,也就是每个block只进行一次激活函数,准确率提升到了81.3%。(感觉这个trick蛮有意思的)
- Fewer normalization layers,只保留dwconv后的一个归一化层,准确率提升到81.4%
- Substituting BN with LN,用LN替代BN, BN主要是用来提高收敛速度和避免过拟合的,但是也可能会对模型的最终性能造成一定的影响。最后将所有的BN替换成LN 准确率提升到81.5%
- Separate downsampling layers,单独的下采样层。这里的修改有点没大看懂,但准确率最后来到了82.0%
个人的一些想法
- 这篇文章通过效仿transformer中的一些设计和trick,通过大量实验将ResNet-50模型准确率硬生生提升了3,4个百分点,可以说是一定程度上打破了未来全部都transformer化的进程。
- 这篇文章中许多调参技巧都值得去进一步进行验证和使用