
基于DL的图像分割综述论文阅读笔记
论文名称:Image Segmentation Using Deep Learning:A Survey
论文链接:https://arxiv.org/pdf/2001.05566
文章主要成果
- 汇总了截至2019年100多种区域分割算法并将他们分为如下十类
- 全卷积网络(FCN)
- 基于图形模型的卷积模型
- 编码器-解码器基础模型
- 基于多尺度分析的金字塔网络模型
- R-CNN基础模型
- 膨胀卷积(空洞卷积Atours)模型和Deeplab系列
- 循环神经网络模型(RNN)
- 基于注意力机制的模型
- 生成模型和对抗训练(GAN)
- 基于主动轮廓的卷积模型
- 对这些基于深度学习的分割算法进行了全面的分析和总结
- 提供了对20多种主流图像分割领域数据集的介绍
- 提供了图像区域分割算法性能评价的常用指标
- 提出未来基于深度学习的图像分割可能存在的方向和挑战
汇总分析
因为是综述性论文,此部分内容过于庞杂,短时间内无法完全理解全部内容,因此此部分仅对我理解的或者感兴趣的进行简要描述与分析,便于后续的学习与分析
主干架构
CNNs
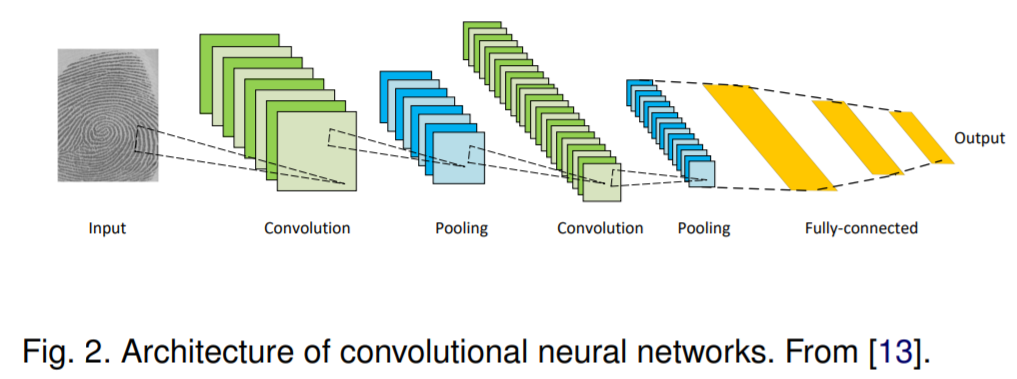
卷积神经网络(CNNs)可以算是深度学习领域最成功被应用最广泛的架构之一。
经典CNN架构主要由三部分组成:
- 卷积层,需要带权重的卷积核,主要用来提取特征
- 非线性激活层,增加网络模型的非线性表达能力
- 池化层,减小特征图分辨率,降低计算量,同时后面层能获得更大的感受野
主要优势:所有感受区域共享卷积核的参数,相比于全连接神经网络极大程度上降低参数量
常见著名的CNN网络:AlexNet,GoogleNet,VGGNet,ResNet
RNNs 和 LSTM
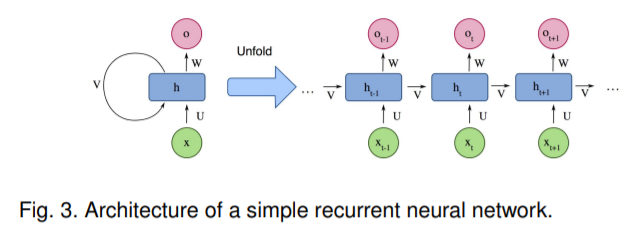
RNN被广泛应用于序列处理的神经网络,序列处理问题简单讲就是后面的数据和前面的数据有联系的问题。可以从上面图中看到每一个输入xt都会和上一层的隐藏层ht-1进行叠加从而输出新的Ot和隐藏层ht,这样确实能有效整合前面的特征与信息,但一旦序列过长就会遇到梯度消失或梯度爆炸问题,这就是长期依赖问题
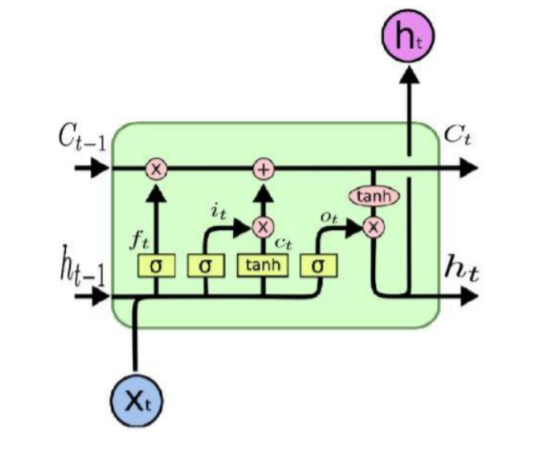
为了解决长期依赖问题,便有了LSTM(长短期记忆),大概就如上图所示在RNN的基础上进行了改进。
感觉近几年RNN和LSTM在CV领域用的不是很多(李弘毅2021机器学习课程里面提到的),所以这里也不进行过多分析,有关LSTM和RNN可以参考这篇博客理解LSTM网络
Encoder-Decoder
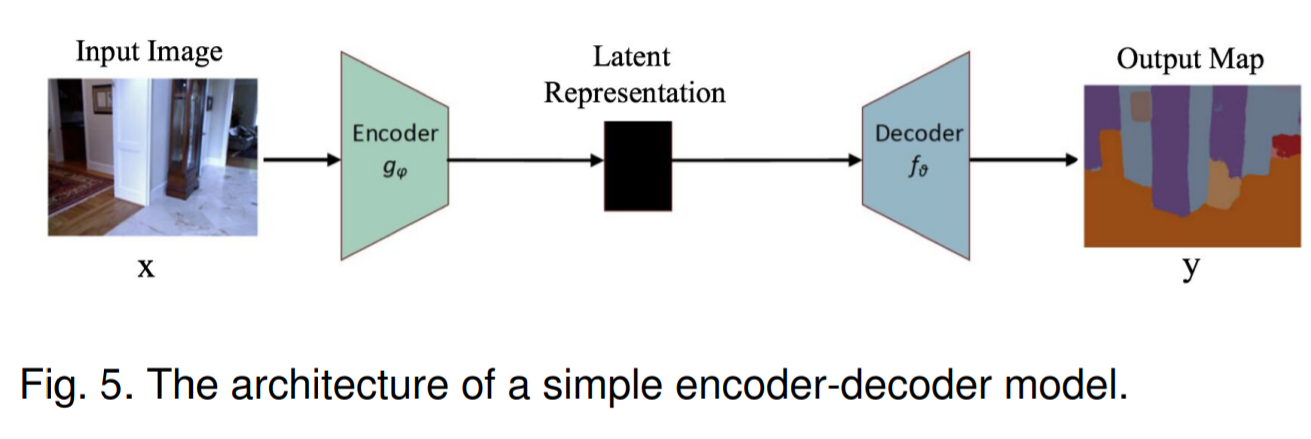
编码器-解码器模型主要是通过两级网络将输入域映射到输出域,由编码函数将输入转换压缩为潜在的空间表示来提取捕获输入的语义信息,再由解码函数来预测潜在空间表示的输出。
GAN
基于DL的图像分割模型
FCN
基于多尺度分析的金字塔网络模型
膨胀卷积(空洞卷积Atours)模型和Deeplab系列
基于注意力机制的模型
主流数据集
PASCAL Visual Object Classes (VOC):
计算机视觉中最受欢迎的数据集之一,带注释的图像可用于5个任务——分类,细分,检测,动作识别和人员布局。 文献中报道的几乎所有流行的分割算法都已在该数据集上进行了评估。 对于细分任务,有21类对象标签-车辆,家庭,动物,飞机,自行车,船,公共汽车,汽车,摩托车,火车,瓶,椅子,餐桌,盆栽,沙发,电视/显示器,鸟 ,猫,牛,狗,马,绵羊和人(如果像素不属于这些类别中的任何一个,则将其标记为背景)。此数据集分为两组,分别是训练集和验证集,分别有1464和1449张图像 。

PASCAL Context
PASCAL VOC 2010检测挑战的扩展,它包含所有训练图像的逐像素标签。 它包含400多个类(包括原始的20个类以及PASCAL VOC分割的背景),分为三类(对象,填充和混合)。 该数据集的许多对象类别太稀疏了; 因此,通常会选择59个常见类别的子集来使用。
Microsoft Common Objects in Context (MS COCO)
另一种大规模的对象检测,分割和字幕数据集。 COCO包含日常复杂场景的图像,其中包含自然环境中的常见对象。 该数据集包含91种对象类型的照片,并以328k图像的形式总共标记了250万个实例。它主要用于分割单个对象实例。 图44显示了给定样本图像的MS COCO标签与先前数据集之间的差异。检测挑战包括80多个类别,提供超过82k图像进行训练,提供40.5k图像进行验证以及超过80k图像进行测试。
Cityscapes
一个大型数据库,专注于对城市街道场景的语义理解 。 它包含来自50个城市的街道场景中记录的各种立体声视频序列集,5k帧的高质量像素级注释以及一组2万帧的弱注释,包括30类的语义和密集像素注释, 分为8类-平面,人,车辆,建筑物,物体,自然,天空和空隙。

ADE20K /MIT Scene Parsing (SceneParse150):
提供用于场景解析算法的标准培训和评估平台。 该基准的数据来自ADE20K数据集,其中包含超过2万张以场景为中心的图像,并用对象和对象部件进行了详尽注释。 基准分为用于训练的2万图像,用于验证的2千图像和用于测试的另一批图像。 该数据集中有150个语义类别。
SiftFlow:
包括来自LabelMe数据库子集的2688个带注释的图像。 256 * 256像素的图像基于8个不同的室外场景,其中包括街道,山脉,田野,海滩和建筑物。 所有图像都属于33个语义类别之一。
Stanford background:
包含来自现有数据集(例如LabelMe,MSRC和PASCAL VOC)的场景的室外图像。 它包含715张具有至少一个前景对象的图像。 数据集按像素进行注释,可用于语义场景理解。 使用Amazon的Mechanical Turk(AMT)获得了该数据集的语义和几何标签。
Berkeley Segmentation Dataset (BSD):
包含来自30个人类受试者的1,000个Corel数据集图像的12,000个手工标记的分割。 目的是为图像分割和边界检测研究提供经验基础。 一半的分割是通过向对象呈现彩色图像获得的,另一半是通过呈现灰度图像获得的。 基于此数据的公共基准包括300张图像的所有灰度和颜色细分。 图像分为200个图像的训练集和100个图像的测试集。
Youtube-Objects:
包含从YouTube收集的视频,其中包括十个PASCAL VOC类的对象(飞机,鸟,船,汽车,猫,牛,狗,马,摩托车和火车)。 原始数据集不包含逐像素注释(因为它最初是为检测对象而开发的,具有弱注释)。 然而,Jain等人手动注释了126个序列的子集,然后提取了帧的子集以进一步生成语义标签。 此数据集中总共有大约10,167个带注释的480x360像素帧。
KITTI
最流行的移动机器人和自动驾驶数据集之一。 它包含数小时的交通场景视频,并以各种传感器模式(包括高分辨率RGB,灰度立体摄像头和3D激光扫描仪)进行记录。 原始数据集不包含用于语义分割的基本事实,但是研究人员出于研究目的手动注释了数据集的各个部分。Alvarez等人从道路检测挑战中生成了323个图像的地面真相,分为道路,vertical和天空3类
常用的评价指标
这部分还是挺有用的,详细记录一下
理论上来说从应用的角度考虑评价一个图像分割算法好坏应该从准确度,处理速度以及存储空间占用情况三个方面考虑,但就理论研究而言目前更重视准确度,因此以下常用指标均从准确度出发给出
Pixel accuracy 像素精度
这种方式就比较直白,直接对图像的每一个像素进行判断,用预测对的像素的数量除以总的像素数量来反映预测的准确度。公式表示为(其中K代表分类数,加上背景总共K+1类,pij代表将类别i的像素预测为类别j)
Mean Pixel accuracy MPA
这种方式是对PA的一种扩展,还是对图像的每个像素进行判断,但这次计算每个类别的正确率,最后求平均值。公式可以表示为
IoU 交并比
语义分割最常用的评价指标,这个根据名字就可以理解,交并比就是指预测值跟真值的交集除以他们两个的并集,用这种方式反映预测的准确度也很好理解,一样的地方越多越好,不一样的地方越少越好。公式表示为
Mean-IoU 平均交并比
主要用于多分类问题,就是对所有类单独做IoU,最后求均值
| 真实情况\预测结果 | 正例 | 反例 |
|---|---|---|
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
Precision 查准率
查准率定义为所有预测是正例的正确率,用公式表示为
Recall 查全率
查全率是指真正例在真实情况为正例中的比例,直白一点就是在一次实验中预测正例正确占全部正例的比率,用公式表示为
F1 Score
查准率和查全率通常是一对互相矛盾的指标,并不单独来评价预测准确率,F1 是二者的调和平均数常被作为重要的评价指标。用公式表示为
Dice coefficient
Dice系数是另一种图像分割领域常用的评价指标(尤其是在医学图像分割领域),可以将其定义为预测图和真实图的重叠区域的两倍,再除以两个图像中像素的总数,用公式表示为 Dice=\frac{2\abs{A\cap B}}{\abs{A}+\abs{B}}
在预测二值图是可以发现